Appendix
A. Prefix trees
Our main result is achieved by reducing a tree inclusion problem to the following problem.
String prefix matching. Consider the following computational problem over strings. Let be a finite alphabet and consider the set of -tuples of strings over . For a string tuple and a set of string tuples , the -dimensional string prefix matching consists in finding the set
This string problem can be solved using a -dimensional prefix tree. We give a short introduction to prefix trees for the string case but refer to standard literature for more details Knuth, 1999. 1999. The Art of Computer Programming: Sorting and Searching, Volume 3. Addison-Wesley, Reading MA.
One-dimensional prefix tree. Let be strings on some alphabet . Given an input string , we wish to find the set of patterns , i.e. is a prefix of .
The prefix tree of is a tree with a tree node for each prefix of a pattern. The children of an internal node are the strings that extend the prefix by one character. The root of the tree is the empty string. Each tree node also stores a list of matching patterns, with each pattern stored in the unique corresponding node. Every prefix tree has an empty string node, which is the root of the tree. For every inserted pattern of length at most nodes are inserted, one for every non-empty prefix of the pattern. Thus a one-dimensional prefix tree has at most nodes and can be constructed in time .
Given an input , we can find the set of matching patterns by traversing the prefix tree of starting from the root. We report the list of matching patterns at the current node and move to the child node that is still a prefix of , if it exists. This procedure continues until no more such child exists. In total the traversal takes time , as every character of is visited at most once.
Note that in theory the number of reported pattern matches can dominate the runtime of the algorithm. We can avoid this by returning the list of matches as an iterator, stored as a list of pointers to the tree nodes matching lists.
Multi-dimensional prefix tree. A -dimensional prefix tree for is defined recursively as a one-dimensional prefix tree that at each node stores a -dimensional prefix tree. Given an input -tuple , the traversal of the -dimensional prefix tree is done by traversing the one-dimensional prefix tree on the input until no child is a prefix of the input, and then recursively traversing the -dimensional prefix tree on . Similarly to the one-dimensional case, the list of matching patterns is stored at prefix tree nodes and reported during traversal. The traversal thus takes time , as every character of is visited at most once.
For tuples of size of words of maximum length , we can bound the number of nodes of the -dimensional prefix tree by . The runtime and space complexity of the construction of the -dimensional prefix tree is thus in , summarised in the result:
B. Lower bound on the number of patterns
Let be the number of port graphs of width , depth and maximum degree . We can lower bound
assuming .
In the regime of interest, is small, so the assumption is not a restriction.
Proof
Let and be integers. We wish to lower bound the number of port graphs of depth , width and maximum degree . It is sufficient to consider a restricted subset of such port graphs, whose size can be easily lower bounded. We will count a subset of CX quantum circuits, i.e. circuits with only gates, a two-qubit non-symmetric gate. Because we are using a single gate type, this is equivalent to counting a subset of port graphs with vertices of degree 4. Assume w.l.o.g that is a power of two. We consider CX circuits constructed from two circuits with qubits composed in sequence:
- Fixed tree circuit: A -depth circuit that connects qubits pairwise in such a way that the resulting port graph is connected. We fix such a tree-like circuit and use the same circuit for all CX circuits. We can use this common structure to fix an ordering of the qubits, that refer to as qubits .
- Bipartite circuit: A CX circuit of depth with exactly CX gates, each gate acting on a qubit and a qubit .
The following circuit illustrates the construction:
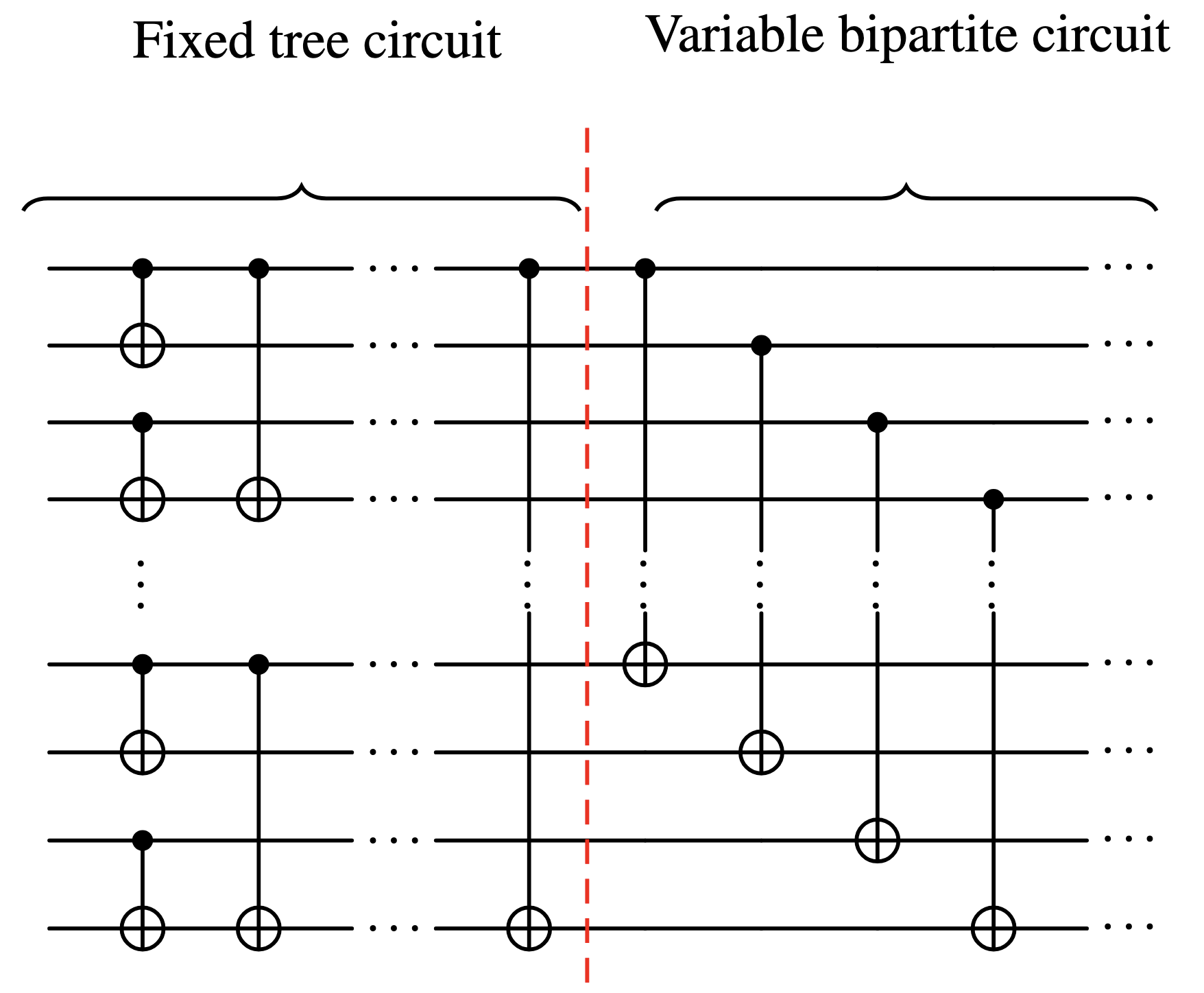
All that remains is to count the number of such bipartite circuits. Every slice of depth 1 must have CX gates acting on distinct qubits. Every qubit to must interact with one of the qubits to , so there are such depth 1 slices. Repeating this depth 1 construction times and using Sterling’s approximation, we obtain a lower bound for the number of port graphs of depth , width and maximum degree at least 4:
where we used to obtain in the last step.